이 논문은 “인공지능이 나의 PC 브라우저에 숨어들어 내가 웹을 서핑하는 과정을 계속 모니터링한다면 무엇을 파악할 수 있을까?”라는 질문에서 출발합니다. 인공지능에게는, 내가 특정 웹 페이지를 얼마나 자주 방문했는지, 얼마나 오랫동안 머물렀는지, 머무는 동안 마우스 커서는 얼마나 움직였는지, 스크롤은 얼마나 많이 했는지, 얼마나 많이 타이핑했는지… 등등이 중요한 자료가 됩니다.
결과론적으로, 이 논문은 사용자가 자신이 흥미로워하는 내용이 담긴 페이지에서는 더 많이 interaction 한다는 결과를 보여주고, 이러한 패턴을 학습한 머신러닝 모델을 구현할 수 있다는 사실을 보여줍니다. 그런데 재미있는 것은, 너무나도 당연해 보이는 이 결과를 얻는 과정에서 몇가지 흥미로운 것들을 발견하였다는 점입니다.
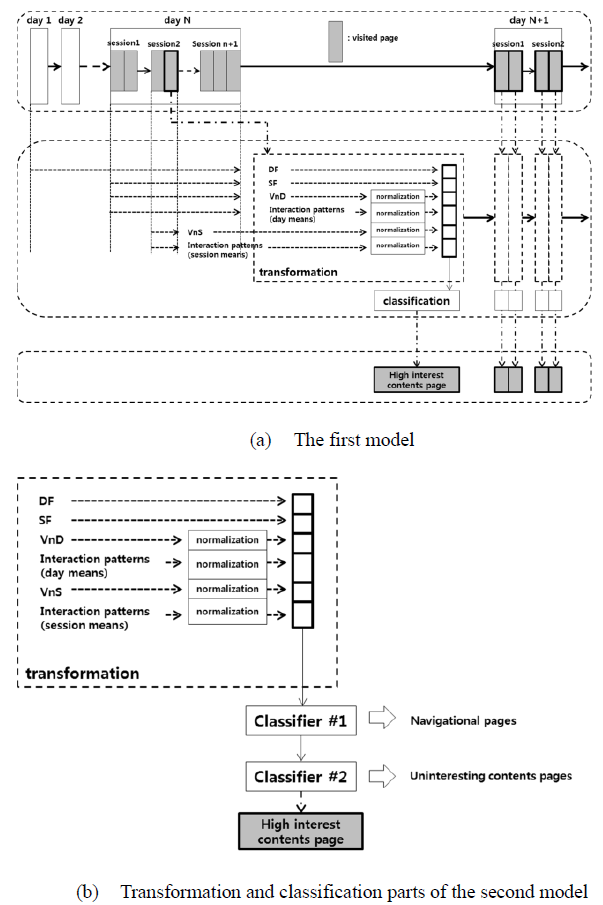
(1) 사용자가 방문하는 페이지들 중에는, 컨텐츠를 소비하는 페이지(contents pages)가 아닌, 다른 페이지로 연결해 주기 위한 페이지 – navigational pages – 가 많이 포함되어 있다. 또한 방문 패턴을 바탕으로 contents pages와 navigational pages를 구분하는 머신러닝 모델을 만들 수 있다.
(2) 사용자는 뚜렷한 검색대상을 염두에 두고 웹을 서핑하기도 하지만 (careful mode), 아무거나 주어지는 대로 받아볼 생각으로 웹을 활용(casual mode)하기도 한다.
(3) Casual mode 하에서 방문한 페이지에서 소비한 내용의 다양성(diversity)은 careful mode 하에서 소비한 내용의 diversity 보다 크다. (즉, careful mode에서는 특정 주제의 컨텐츠를 살펴보는 경향이 있는 반면에, casual mode 에서는 특정한 주제보다는 다양한 주제의 컨텐츠들을 두루두루 소비한다. 따라서, 실시간 추천 서비스를 디자인할 때, 사용자가 어떤 모드 하에서 웹을 활용하고 있는 지를 먼저 파악할 필요가 있다.
(4) Careful mode에서는 사용자가 찾고자 하는 타겟 정보를 파악하여 그것과 관련된 컨텐츠들을 추천해야 하며, casual mode 에서는 다양한 컨텐츠를 확장하여 추천해 줄 수 있다. 이러한 방법을 통해 서로 모순되는 측면이 있는 information overload 문제와 overspecialization 문제를 동시에 해결할 수 있다. (information overload 문제를 해결하려면 사용자의 의도에 맞는 컨텐츠만을 제공해야 하는데, 그럴 경우, 너무 비슷한 컨텐츠만을 지속적으로 제공하게 되어 overspecialization 문제가 발생합니다.)
(5) 사용자가 현재 어떤 모드 하에서 웹을 활용하고 있는지 파악하는 모델을 어렵지 않게 구현할 수 있다.
더 나아가, careful mode에서 소비한 컨텐츠들의 주제의 다양성과 casual mode에서 소비한 컨텐츠들의 주제의 다양성을 수치로 비교 분석한 결과도 제시합니다. (꽤 인기있었던 graphical model 중의 하나인 Latent Dirichlet Allocation 기반)
<더보기> 아래의 외부링크 클릭


