문서 공간
일반적으로 문서들은 수많은 다른 문서들과 함께 존재합니다. 문서들로 구성된 공간이 만들어지는 것이죠. 따라서 하나의 문서는 문서들로 구성된 공간 상의 점이라고 할 수 있습니다. 문서 하나의 정보, 즉 점이 포함한 정보의 의미와 가치를 충분히 파악하려면 이 점이 위치한 좌표에 대해서도 알아야 합니다. 문서들로 구성된 공간에서의 위치와 맥락을 살펴봐야 한다는 의미지요.
문서들로 구성된 공간에서의 특정 문서의 좌표를 알아내기 위해서는 좌표 체계가 필요합니다. 좌표 체계를 만들려면 문서 공간에 포함된 전체 지식의 구조를 파악해야 하죠. 지식의 구조를 파악하는 것은 모든 문서들을 서로 묶거나 연결하여 각 문서 안에 포함된 정보의 분포와 정보들 간의 관련성을 찾아내는 것입니다.
그런데 문서들로 구성된 공간을 설명할 좌표 체계를 만들고, 좌표 체계 상에서의 각 문서들의 위치를 찾는다는 게 구체적으로 어떤 것인지 상상이 잘 가지 않습니다.
이번 포스트에서 몇 가지의 예를 들어 보겠습니다.
정보의 구조와 흐름을 파악하기
대형 병원의 홈페이지에는 각 질병에 대해 설명한 자료들이 제공됩니다. 서울대학교 병원 홈페이지에 약 760 페이지, 연세대학교(세브란스) 병원 홈페이지에 약 230 페이지, 고려대학교 병원 홈페이지에 약 450 페이지, 그리고 아산병원 홈페이지에는 약 1630 페이지의 질병 설명 자료들이 있습니다. 전부 합하면 3000 페이지 정도 되네요. 각 문서는 하나의 질병에 대해, 병명, 정의, 증상, 원인, 진단법, 검사법, 치료법, 경과 및 합병증, 예방 및 생활 가이드 등과 같은 여러 섹션으로 나누어 설명합니다.
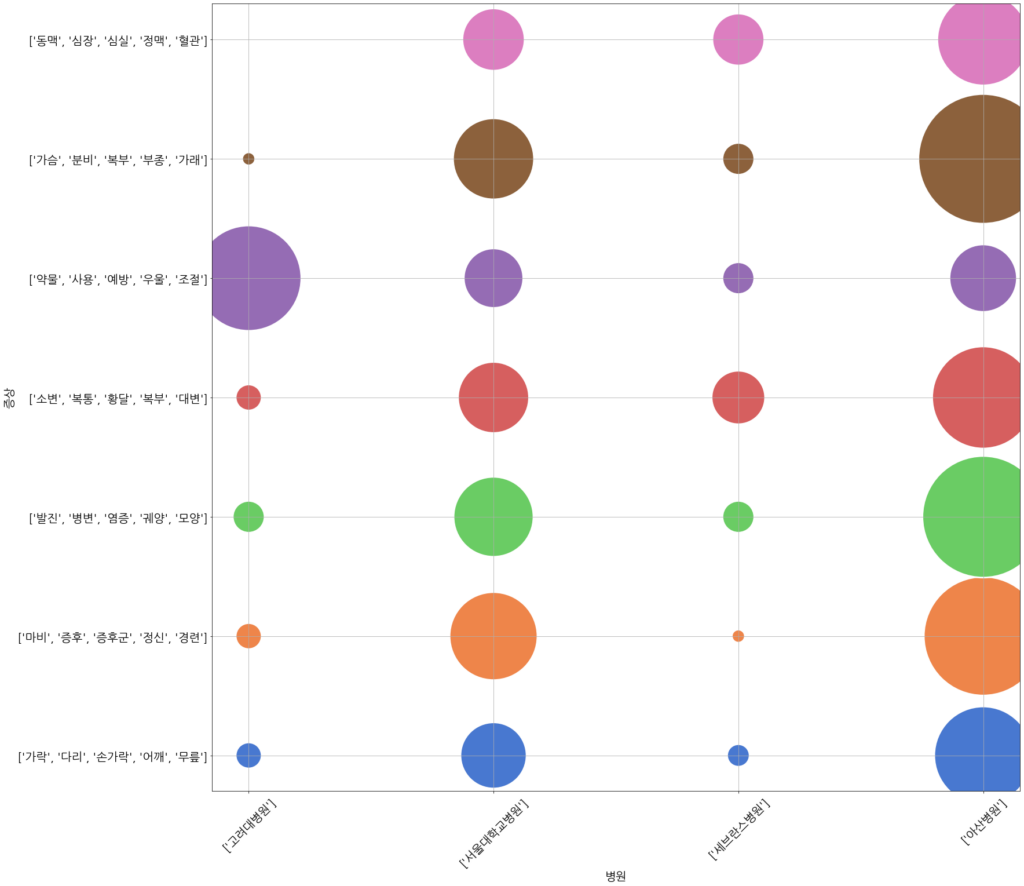
좌표 체계를 만들기 위해 모든 질병 문서들을 ‘증상’ 섹션의 내용의 유사도를 바탕으로 그룹화하고 각 그룹의 내용을 대표하는 주요 키워드들을 추출하면 그림 2의 Y축의 눈금에 표시된 것과 같이 나누어집니다. 모든 문서는 Y축의 7개 그룹들 중 하나에 속하게 되는 거죠. (문서를 자동 그룹핑하고 각 그룹의 주요 키워드들을 추출하는 과정에는 여러가지 알고리즘을 활용할 수 있는데, 이것에 대해서는 추후에 기회가 있을 때 설명하겠습니다.) X축 좌표는 문서를 공개한 병원 별로 구분한 것입니다. 따라서, 모든 문서들은 Y축의 7개 그룹들 중 하나, 그리고 X축의 병원들 중의 하나에 속하게 되는 거죠. 여러 개의 문서들이 동일한 좌표에 속할 수 있게 되는데, 특정 좌표에 속한 문서들의 수가 많을 수록 해당 좌표에 그려진 원의 크기가 커집니다.
위의 그림의 Y축을 보면 각 그룹을 대표하는 키워드들이 각 그룹 내 증상들의 특성을 파악할 수 있게 한다는 것을 알 수 있습니다. 저는 의료 전문가는 아니지만, 순환기 관련 그룹, 호흡기 관련 그룹, 정신질환 관련 그룹, 비뇨기 관련 그룹, 소화기 관련 그룹, 신경과 관련 그룹, 정형외과 관련 그룹 등으로 나누어진 듯 합니다.
그리고 서울대학교 병원과 아산병원에서 제공하는 질병 문서들에는 거의 모든 증상에 대한 내용이 포함되어 있는 것에 비해, 고려대학교 병원과 세브란스 병원에서 제공하는 문서들은 일부 증상 그룹에 대한 문서의 수가 상대적으로 작아 보인다는 사실도 알 수 있습니다. (전체 문서들 중에 아산병원의 문서 수가 가장 많고, 그 다음이 서울대학교병원이라는 점도 고려해야 합니다.)
고려대학교 병원에서 제공하는 질병 문서들 중에는 정신 질환과 관련된 것들의 비중이 상대적으로 높은 듯 합니다.
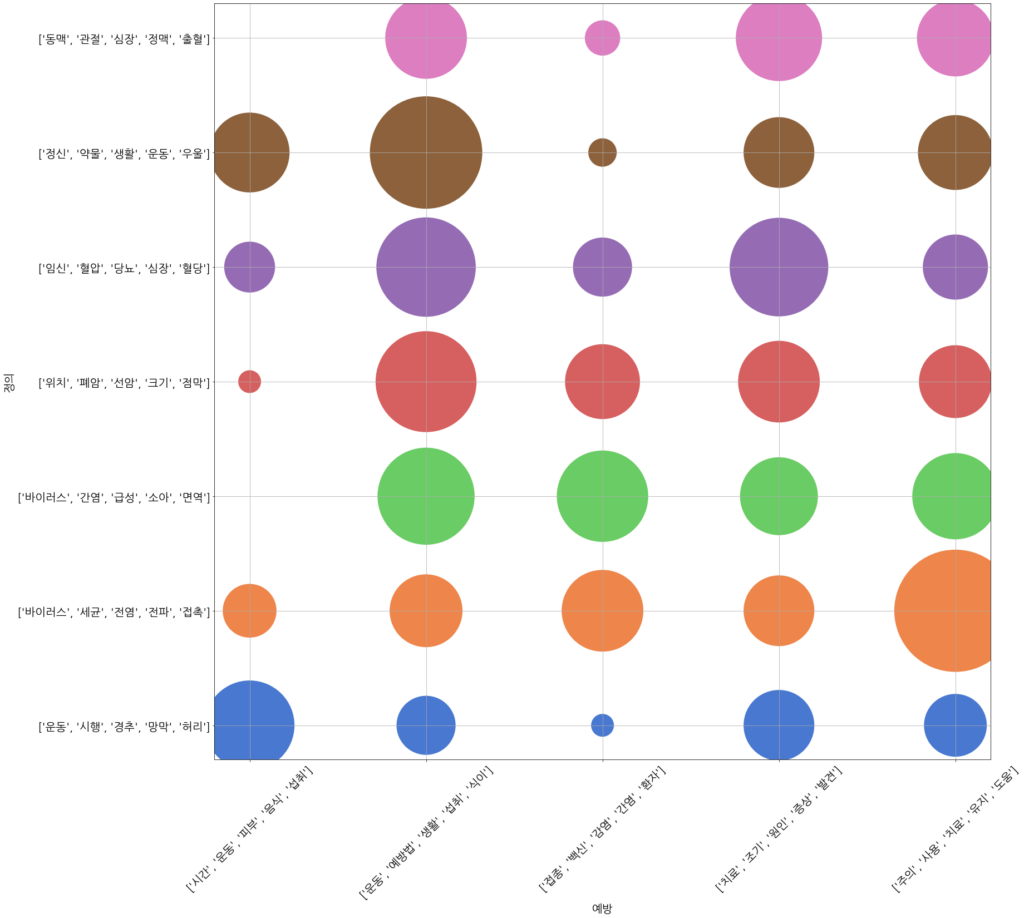
질병 문서의 ‘정의’ 섹션과 ‘예방’ 섹션의 내용을 바탕으로 좌표 체계를 만들면 위의 그림과 같은 형태가 됩니다. X축의 예방 그룹들 중에서 운동, 생활, 조기 발견 등과 같은 내용을 담은 예방법은 Y축을 따라 고루 분포되는 패턴을 보입니다. 가장 기본적이면서도 중요한 예방법들이라고 볼 수 있지 않을까 합니다. 이에 비해 백신이나 감염과 관련된 예방법은 순환기 관련 질병, 정신과 관련 질병, 정형외과 관련 질병들과는 상대적으로 관련성이 적어 보입니다. 운동 및 음식 섭취와 관련된 예방법이 면역 관련 질병이나 순환기 관련 질병과 관련성이 적게 보이는 이유에 대해서는 좀 더 파헤쳐 볼 필요가 있어 보입니다.
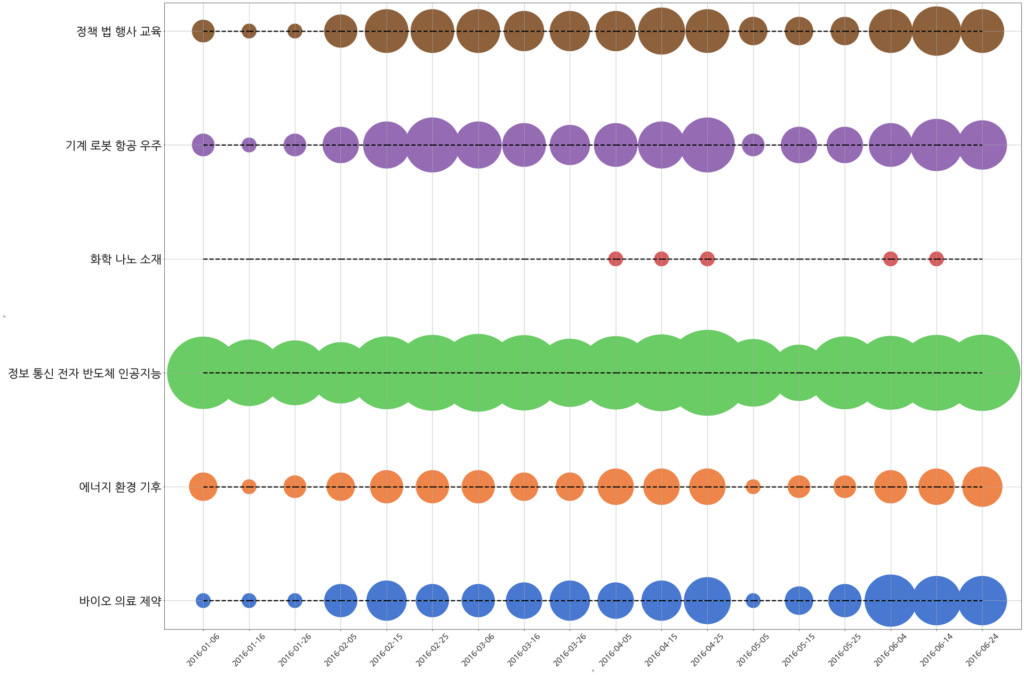
위의 그림은 알파고 이슈가 대한민국을 흔들었던 2016년 상반기(1월\~6월)에 출판된 IT/과학 분야의 뉴스 기사들의 분포와 흐름을 나타냅니다. X축을 따라 가면 시간에 따른 (10일 단위) 주제 별 기사의 분포를 알 수 있습니다. Y축은 모든 기사들을 본문 내용의 유사도를 바탕으로 그룹화하고 각 그룹의 내용을 대표하는 주요 키워드들을 추출한 결과를 표시하고 있습니다.
이 그림을 보면 정보통신, 반도체, 인공지능 분야의 기사의 비중이 확실히 가장 크다는 것을 알 수 있습니다. 이와 달리 화학, 소재 분야의 기사는 상대적으로 양이 적습니다. 대략적으로 2016년 2월부터 전체 기사의 수가 늘어났다는 것을 알 수 있고, 2016년 5월 초에는 전체적인 기사의 수가 잠시 줄어들었다는 것도 알 수 있습니다. (2016년 5월 초에는 무슨 일이 있었던 걸까요?)
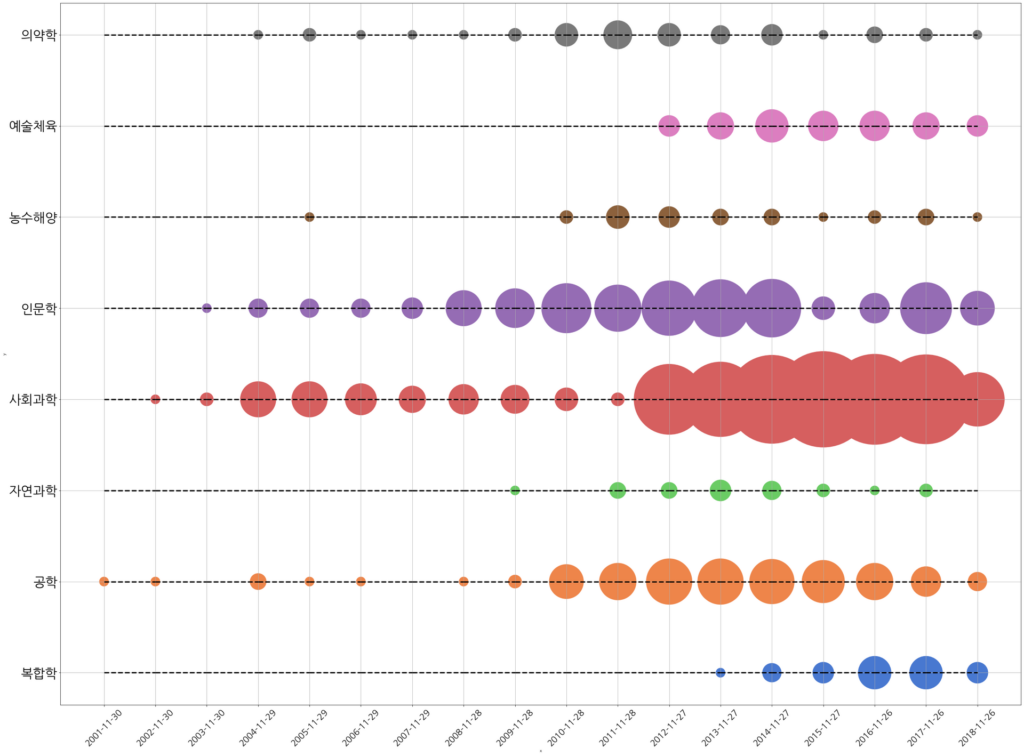
위의 그림은 2001년에서 2018년까지 국내 학술지에 출판된 학술 연구 논문들의 분포와 흐름을 나타냅니다. Y축에 따라서는 논문의 분야를 구분하였습니다. 전체적으로 사회과학, 인문학 및 공학 분야의 논문의 수가 가장 많으며, 복합학, 농수해양, 예술체육 분야의 논문들은 2011년 이후부터 본격적으로 데이터에 나타나고 있습니다.
위의 그림을 통해서 본 데이터에는 각 분야의 논문의 분포가 시간에 따라 어떻게 변화하는가를 충분히 파악할 수 있습니다. 그리고 어쩌면 이것은 학술 연구의 주제 별 비중의 변화를 표현한다고 볼 수 있겠지요.
2008년에서 2011년 사이에는 인문학 분야의 논문이 가장 많았으나 2012년부터는 사회과학 분야의 논문의 수가 급격하게 많아집니다. 공학 분야의 논문은 2010년부터 증가하다가 2015년부터 감소하는 추세를 보입니다. 복합학은 2013년에 처음 나타나기 시작해서 수치가 늘어나다가 2018년에는 잠시 주춤했습니다. 복합학이 여러 분야의 학제간 연구나 융합 연구분야를 의미하는 것 같은데, 2013년부터 본격적으로 활성화된 듯 합니다.
이 데이터에 모든 국내 학술지의 논문이 포함되어 있는 것은 아니므로 위와 같은 추세가 한국의 연구분야 전체에 나타난 것이라고 보기는 어렵지만 만약 전체 논문 세트에서 특정 추세가 나타난다면 그 의미를 해석해 보는 것도 흥미로울 것입니다.
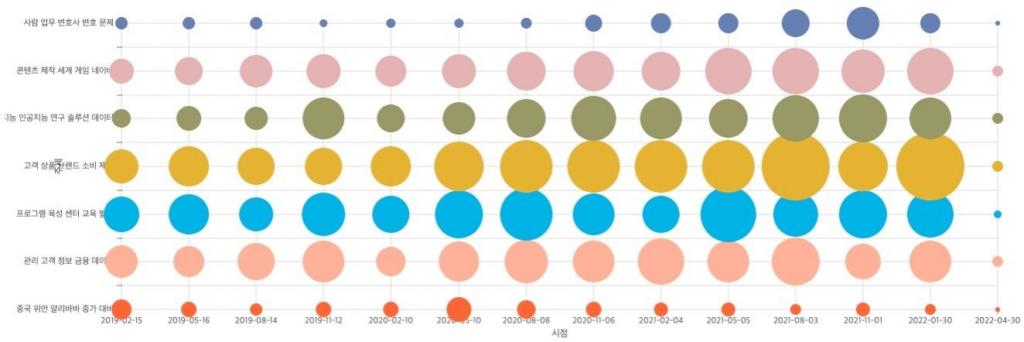
위의 그림은 2019년 초부터 2022년 3월 말까지 스타트업 미디어에 출판된 기사들에 나타난 정보의 구조와 흐름을 나타냅니다. 전체 기간을 90일 간격으로 나누고 각 기간의 중간에 해당하는 날짜를 X축에 표시하였습니다. 유사한 주제의 기사들끼리 자동으로 묶은 뒤 해당 묶음에서 주요 타이틀을 자동 추출한 결과를 Y축에 표시하고 있습니다.
이 데이터에 적용한 알고리즘은 전체 정보를 아래의 7가지의 그룹으로 구분하였습니다.
- 금융 관리 고객 정보 데이터
- 중국 위안 거래 증가 조사
- 고객 판매 브랜드 상품 배송
- 콘텐츠 제작 교육 출시 게임
- 솔루션 데이터 지능 선정 연구
- 프로그램 센터 육성 중소 경제
- 사람 업무 이유 변호 변호사
추출된 타이틀을 보면 스타트업 미디어의 특징이 잘 나타나게끔 타당하게 나누어진 듯 합니다. (실제로 각 그룹에 들어있는 기사들의 내용에 대해서는 앞으로 설명할 예정입니다.) 상대적으로 정보의 양이 적어 보이기는 하지만 “중국 위안 거래 증가 조사”의 타이틀로 묶인 그룹이 있는 것이 흥미로운데, 한국의 스타트업계에서는 중국과 관련된 정보가 꽤 큰 비중을 차지한다고 해석해도 되지 않을까 합니다.
인공지능 관련 내용은 “솔루션 데이터 지능 선정 연구” 그룹에 주로 들어있을 듯 하고, 스타트업을 지원하는 사업에 대한 내용은 “프로그램 센터 육성 중소 경제” 그룹에, 스타트업의 인적 구성이나 법률, 특허 등과 관련된 정보는 “사람 업무 이유 변호 변호사” 그룹에 포함되어 있을 것 같아 보입니다. (실제로도 그렇습니다.)
참고로, X축 상에서 가장 마지막에 나타난 그룹들의 크기가 다른 기간의 그룹들에 비해 작은 이유는, 90일 간격으로 나누다 보니, 다른 기간에 비해 마지막 기간의 길이가 짧아졌기 때문입니다.
NEXT…
좌표 체계를 생성하고, 문서들로 구성된 공간을 위와 같이 그려 보니, 어떤 주제의 정보가 얼마나 들어있는지, 그리고 지식의 분포 패턴이 어떻게 나타나는지 대략적으로 파악할 수 있네요. 이런 정보는 검색 기능이 제공해 주지 않습니다.
문서 하나하나를 읽기 전에 이런 정보를 미리 파악할 수 있다면 해당 문서의 정보를 이해하는 데에 도움이 될 수 있습니다.
그런데, 욕심을 좀 더 내어서, 전체적인 구성과 분포만 보고 끝낼 것이 아니라, 내가 찾고자 하는 세부 정보가 문서 공간 상의 어느 곳에 위치하는지, 얼마나 넓게 분포하는지, 어떤 정보들과 유사한 그룹으로 묶여 있는지, 실제로는 어떤 문서에 들어있는지 등과 같은 세부정보까지 알 수 있으면 좋겠다는 생각이 듭니다. 이런 정보들까지 알게 되면 혹시 내가 찾고자 하는 세부 정보가 어떤 맥락에서 나온 것인지 파악하는데 큰 도움이 되지 않을까요?
인포리언스는 기술을 연구하고 개발하면서 각 기술의 활용성과 가능성을 검토해 나가고 있습니다.


