
Screenshot
지식의 분포와 흐름, 진화과정을 추적하고 해석하는 시스템
인포리언스는 대용량의 문서 세트에 포함된 “지식의 분포와 흐름, 진화과정을 추적하고 해석하는 시스템 (가칭:ShadowKernel)”을 개발하고 있습니다.
ShadowKernel은 다음과 같은 기능을 탑재하고 있습니다.
- 지식의 구성과 흐름을 시각화
- 특수한 흐름이 나타난 부분에 대한 해석을 자동 추출
- 분석한 내용을 바탕으로 사용자의 질문에 응답
본 글은 ShadowKernel을 활용하여 작성하였습니다.
Visual Grounding이란?
**`* 이 그림은 ChatGPT로 생성한 것입니다.
Visual Grounding은 텍스트로 설명된 객체를 이미지에서 식별하는 기술로, 컴퓨터 비전과 자연어 처리 기술의 긴밀한 결합을 필요로 합니다.
예를 들어, “가장 큰 코끼리 옆에 있는 붉은 공”과 같은 설명에 대해, 컴퓨터 시스템은 이 공을 이미지 내에서 찾아내야 합니다. 이 과정에서 머신러닝 모델은 이미지와 텍스트 모두에서 특징을 추출하고 융합하여, 객체를 검출하거나 추적하는 작업을 수행합니다.
이 기술이 잘 구현되면, 정밀한 객체 인식과 추적을 자연어 설명을 기반으로 수행하게 하여, 사람과 컴퓨터 시스템 간의 자연스러운 상호작용을 가능하게 합니다.
따라서 자율주행 차량, 증강 현실(AR)/가상 현실(VR), 로보틱스와 같은 분야에서 구체적으로 응용할 수 있습니다. CCTV 영상을 분석하는 과정에서도 큰 역할을 할 수 있겠지요.
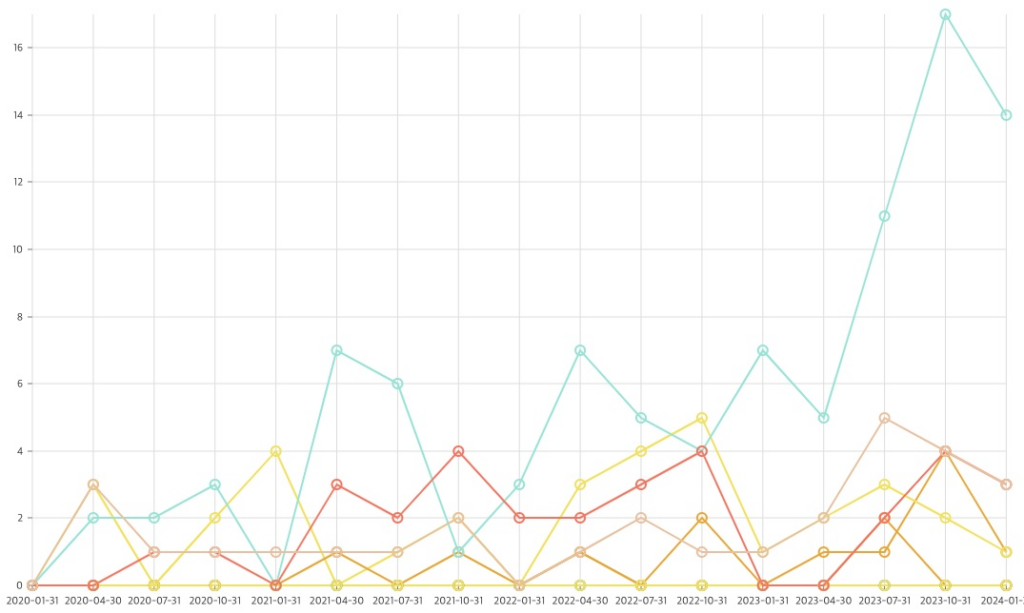
10개의 주요 컴퓨터 과학 분야에 나타난 Visual Grounding의 시간에 따른 비중은 위의 그림과 같습니다. 그림에 의하면, 시간에 따라 가장 급격하게 비중이 상승하는 형태를 보이는 분야가 있습니다. 이 분야는 Computer Vision 입니다. “Visual”이라는 키워드가 들어있으니, 어쩌면 당연한 결과라고 볼 수도 있습니다.
그런데, 오래 전부터 Visual Grouding 관련 연구가 계속 이루어져 왔음에도 불구하고, 최근에 들어서 갑자기 비중이 커지는 이유는 무엇일까요? 혹시 Visual Grounding을 가능하게 하는 주요한 세부 기술에 새로운 돌파구가 생긴 것은 아닐까요?
구체적인 연구 흐름은 어떨까?
최근 몇 년간의 Visual Grounding과 관련한 연구 동향을 살펴보면, 이 분야는 다양한 방법론과 모델을 통해 점점 더 발전하고 있습니다. 전체적으로 볼 때, Visual Grounding은 비전과 자연어 사이의 alignment를 확립하는 것에 중점을 두고 있으며, 이것이 가능해질 경우, 모델이 시각적 자료에서 언어적 표현에 해당하는 영역을 정확히 식별할 수 있습니다. 연구목적들 중 하나는 이 과정에서 발생할 수 있는 언어와 visual 정보 사이의 confounding bias를 해결하는 것이며, 많은 연구들이 다양한 접근 방법과 개선 방안을 제시하고 있습니다. (일반적인 의미에서 confounding bias란, 특정 원인과 결과 사이의 관계를 왜곡시키는 미지의 변수로 인해 발생하는 편향을 의미합니다.)
2021년에는 기존의 접근 방식이 시각적 근거를 제대로 마련하지 못해 언어적 사전 지식에 의존하거나, 허구를 만들어내는 경향이 있었음을 지적합니다.
2022년 3월에는 End-to-End Visual Grounding 프레임워크에 QRNet을 적용하고, SeqTR이라는 단순하지만 범용적인 네트워크를 제안했습니다. 이 네트워크들은 기존의 Weakly-Supervised 기반 Visual Grounding 방법보다 우수하거나 비슷한 성능을 보여주었고, 과거의 다른 방법론으로는 추출할 수 없는 정보를 추출할 수 있었다고 합니다.
2022년 6월에는 Attention Mask Consistency(AMC)라는 개념이 소개되었습니다. 이것은 자연어 표현에 해당하는 이미지 영역을 세그멘테이션하는 모델로서, 기존의 방법보다 더 우수한 Visual Grounding 결과를 생성하는 것으로 나타났습니다.
2022년 9월에는 객체 탐지와 Visual Grounding에서 경쟁력 있는 성능을 보여주는 LOUPE가 소개되었고, 그와 함께 PARsing And Visual GrOuNding(ParaGon)이라는 새롭고 획기적인 방법이 제안되었습니다.
시간이 좀 더 흐르면, 텍스트와 비전 사이의 관계를 더욱 효과적으로 활용하기 위한 새로운 모델과 접근 방법이 제시되며, Visual Grounding을 통한 객체 감지와 이미지-텍스트 검색 등의 다양한 응용에서 좋은 성능을 달성한 연구 결과가 나타납니다.
2022년 말에서 2023년에 걸쳐 Weakly-supervised Visual Grounding을 발전시키기 위한 새로운 패러다임인 Position-guided Text Prompt(PTP)가 제안되며, 이는 Visual Grounding을 ‘fill-in-the-blank problem’으로 재구성하여 Vision Language Pre-trainded 모델의 부족함을 해결하고자 했습니다. 그리고 최신 연구에서는 사전 훈련된 Generative Diffusion 모델을 Visual Grounding 과정에 적용하고, Set-of-Mark(SoM)이라는 새로운 visual prompting 방법을 제시하여 Visual Grounding의 능력을 최대한 발휘하도록 합니다. 그리고 Large Language Model과 Visual Grounding 모델을 사용하여 자동으로 학습 데이터셋을 생성하는 방법론도 제시되었습니다. 이 방법은 기존의 SOTA(State of the Art) 제로샷 성능을 최대 19.5% 향상시켰다고 합니다.
이러한 연구들은 Visual Grounding 분야에서 기술적 진보를 이루고 새로운 접근 방식을 탐색함으로써, 비전과 언어의 연결을 좀 더 밀접하게 하여 보다 정교하고 효과적인 모델을 개발하는 데 중요한 역할을 합니다.
Visual grounding을 indoor 환경에서 활동하는 로봇에 적용하는 과정에는 어떤 기술적 문제가 해결되어야 할까?
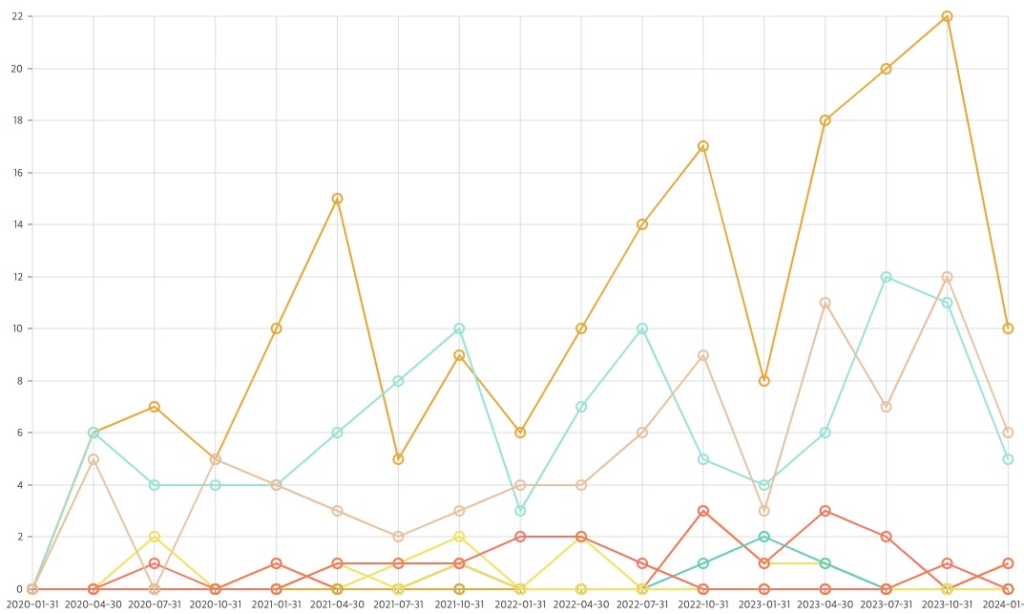
이 질문을 가장 비중있게 다루고 있는 3개의 분야는 Robotics, Computer Vision, 그리고 Computational Linguistics 분야입니다. (위의 그림의 상위 3개 그래프)
이와 같은 세 분야에서 언급한 주요 기술적 문제는 다음과 같습니다.
Robotics 분야
- 실내 환경에서 활동하는 로봇에 ‘Visual grounding’을 적용하는 과정에서는 여러 가지 기술적 문제가 발생할 수 있습니다.
- 첫째로, 실제 환경에서 객체를 식별하고 이해하는 데 필요한 풍부한 라벨링된 데이터가 부족하거나, 복잡한 언어 쿼리를 처리하는 데 한계가 있을 수 있습니다.
- 둘째로, 로봇이 사람들과 밀접하게 상호 작용해야 하는 환경을 이해하고 탐색하려면, 완벽한 Ground-Truth를 기반으로 한 표준화된 테스트가 필요합니다.
- 셋째로, 수많은 객체 중에서 특정 객체를 가리키고 그것을 제대로 잡아야 하는 ‘referring grasp’ 작업은 복잡한 실내 환경에서 특히 어려울 수 있습니다.
- 마지막으로, 실내 공간의 복잡한 구조, 로봇 시스템의 실시간 위치 결정과 위치 오차 문제로 인해 실내 환경에서의 정확한 3D 매핑을 구축하는 것이 어려울 수 있습니다.
Computer Vision 분야
- ‘비주얼 그라운딩(Visual Grounding)’은 로봇이 실내 환경에서 효과적으로 활동하려면 필수적으로 갖추어야 할 능력입니다. 그러나 이를 실행하는 데는 여러 기술적 해결해야 할 문제들이 존재합니다.
- 먼저, 다양한 명령에 따른 로봇의 행동을 구현하는 것은 복잡한 자연어 쿼리를 다루는 과정 때문에 어렵습니다.
- 다음으로, 로봇이 대상물을 감지하는 과정에서 ‘물체 가리기(Occlusion)’ 문제가 발생할 수 있습니다.
- 마지막으로, 로봇이 사용자 지시에 따라 물체를 효과적으로 조작하려면, Visual Grounding과 Grasping 능력의 통합이 요구됩니다.
Computational Linguistics 분야
- Visual grounding은 로봇이 자신의 환경을 이해하고, 객체를 조작하며, 주변 환경에 기반한 질문에 답하게 해주는 중요한 역량입니다. 하지만 현존하는 접근법들은 대부분 방대한 데이터에 의존하거나 복잡한 언어 쿼리를 처리하는 데 제한이 있습니다.
- 또한, 언어 명령을 기반으로 로봇을 작업시키기 위해 사용되는 ‘EmBert’와 같은 기술에서도, 언어 명령과 시각 관찰 결과를 연결하는 것은 어려운 도전 과제입니다.
- 자율주행 차량과 인간과의 상호작용에서도, 특정 영역이나 물체를 시각적으로 파악하고 이를 언어적으로 연결하는 ‘language grounding’은 필수적인 요소로, 이에 대한 정확한 이해 없이는 입력 장면과 명령에 대한 충분한 이해가 불가능할 수 있습니다.
그렇다면, ‘Language Grounding’과 ‘Visual Grounding’의 차이점은 무엇일까?
‘Language Grounding’과 ‘Visual Grounding’은 언어와 시각 정보를 서로 연결하는 방식에서 차이를 보입니다.
‘Language Grounding’은 언어의 상징적 표현(예: 단어)를 외부 세계의 풍부한 지각적 지식에 연결하는 것을 목표로 합니다. 일반적으로 텍스트와 시각 정보를 공통의 공간, 즉 ‘Grounded space’에 임베딩하여 두 모달리티 간의 명확한 연관성을 찾고자 합니다. 이를 위해, 텍스트 공간과 ‘Grounded space’ 간의 합리적인 Grounded 매핑을 결정하는 방식으로 모달리티를 통합합니다.
반면, ‘Visual Grounding’은 시각적 객체와 그들의 언어 entity 간의 대응 관계를 구축하는 것을 목표로 합니다. 이미지-캡션 쌍만을 이용하는 Weakly-Supervised 방식이 효과적인 방법으로 간주됩니다.
결국, ‘Language Grounding’은 텍스트 정보를 이해하고 해석하는데 집중하며, ‘Visual Grounding’은 시각적 객체를 언어로 설명하고 이해하는데 초점을 맞춥니다.
참고문헌 리스트
- https://arxiv.org/abs/2111.12872
- https://arxiv.org/abs/2111.12085
- https://arxiv.org/abs/2112.15324
- https://arxiv.org/abs/2203.15442
- https://arxiv.org/abs/2202.10292
- https://arxiv.org/abs/2203.08481
- https://arxiv.org/abs/2203.16265
- https://arxiv.org/abs/2205.00272
- https://arxiv.org/abs/2202.03052
- https://arxiv.org/abs/2205.12005
- https://arxiv.org/abs/2206.15462
- https://arxiv.org/abs/2206.08358
- https://arxiv.org/abs/2205.04725
- https://arxiv.org/abs/2206.09114
- https://arxiv.org/abs/2207.05703
- https://arxiv.org/abs/2210.04183
- https://arxiv.org/abs/2208.02515
- https://arxiv.org/abs/2208.09374
- https://arxiv.org/abs/2210.12997
- https://arxiv.org/abs/2210.09263
- https://arxiv.org/abs/2210.00215
- https://arxiv.org/abs/2212.05561
- https://arxiv.org/abs/2301.09045
- https://arxiv.org/abs/2212.09737
- https://arxiv.org/abs/2211.15516
- https://arxiv.org/abs/2211.14739
- https://arxiv.org/abs/2302.11252
- https://arxiv.org/abs/2303.12027
- https://arxiv.org/abs/2306.08498
- https://arxiv.org/abs/2305.11497
- https://arxiv.org/abs/2307.05873
- https://arxiv.org/abs/2305.10714
- https://arxiv.org/abs/2305.14998
- https://arxiv.org/abs/2307.11558
- https://arxiv.org/abs/2309.01141
- https://arxiv.org/abs/2310.09478
- https://arxiv.org/abs/2310.14374
- https://arxiv.org/abs/2310.11441
- https://arxiv.org/abs/2310.17770
- https://arxiv.org/abs/2310.10975
- https://arxiv.org/abs/2209.03714
- https://arxiv.org/abs/2002.02734
- https://arxiv.org/abs/2206.08823
- https://arxiv.org/abs/2104.07500
- https://arxiv.org/abs/2103.12989


