이번 포스트는 연구개발특구진흥재단에서 발주하고 에이아이프렌즈학회 및 (주)에이프리카가 주관하는 2021년 AI 특성화기업 역량강화 지원사업의 일환으로 인포리언스가 수행한 (주)트레이더스의 파일럿 제작 지원 프로젝트의 결과를 바탕으로 구성하였습니다. 본 프로젝트에서는 복수의 해외 사이트들에서 수집한 공개 데이터를 활용하였음을 미리 말씀드립니다. 그리고 구체적인 데이터 처리 과정이나 구현 모델 등과 같은 자세한 사항들에 대해서는 이 글에서 모두 공개할 수 없다는 점도 미리 밝힙니다.

열차와 전철은 우리의 삶에서 빼놓을 수 없는 중요한 교통수단입니다. 여행을 할 때에도, 평소에 출퇴근을 할 때에도 말이죠. 최근에는 기관사 없이 자동으로 운행하는 전철도 운행되고 있습니다. 신규 노선에 지능적인 서비스를 탑재하려는 노력도 진행되고 있다고 합니다. 이렇듯 철도 운행 분야는 인공지능 기술이 아주 잘 응용될 수 있는 대표적인 활용처죠. 물론 데이터가 잘 확보될 수 있다면 말이죠.
이번 포스트에서는 열차가 운행하는 동안 기록되는 데이터에 인공지능 모델을 적용해 본 기초 연구의 결과를 간략하게 소개하겠습니다.
바쁜 출근 시간에 열차에 탑승하려고 하는데 열차가 제 시간보다 늦게 도착하여 짜증이 났던 경험을 하신 분들이 꽤 많으실 겁니다. 그래서인지 몰라도 열차 운행 데이터를 바탕으로 열차의 지연 정도를 정확히 예측하려는 시도를 하는 경우가 꽤 있더군요. 또한 열차의 운행 상태에 이상 패턴이 발생하면 최대한 빨리 탐지하는 것도 중요하지요. 안전을 위해서 빨리 조치를 취해야 하기 때문에 그렇고, 더 나아가 해당 열차를 타기 위해 기다리고 있을 승객들에게 상황을 빨리 전달하기 위해서도 그렇습니다. 생각해 보면, 열차, 플랫폼, 선로 또는 역 주변 상황에 이상이 생기면 열차의 운행 상태에 변화가 발생하게 되고 열차가 제 시간에 도착하지 못하게 될 가능성이 커지겠지요. 즉, 열차의 운행 상태와 지연 정도는 서로 뗄 수 없는 밀접한 관련이 있는 겁니다. 따라서 가장 먼저 열차의 운행 상태에 나타난 이상 패턴을 탐지하는 모델을 만들어 보고 이에 추가하여 열차의 지연 정도를 예측하는 모델을 구현해 본 결과를 살펴보겠습니다.
운행 상태에 나타난 이상 탐지
일반적으로 Anomaly Detection, 즉 이상 탐지 모델을 구현할 때에는 정상적인 데이터의 특성을 학습한 모델이 테스트 과정에서 이상 패턴을 담은 데이터를 입력받을 때 정상적인 데이터보다 더 큰 오차를 출력하도록 합니다.
첫번째 실험에서는 열차의 운행 구간을 작은 구간으로 나누고 모든 구간에서의 차량 속도, 앞차와의 거리, 구간 내에서 동시에 운행 중인 차량의 수 등을 모두 학습하여 일부 항목에 이상 패턴이 발생하였을 때 이를 자동으로 탐지할 수 있는 Anomaly Detection 모델을 구현했습니다.
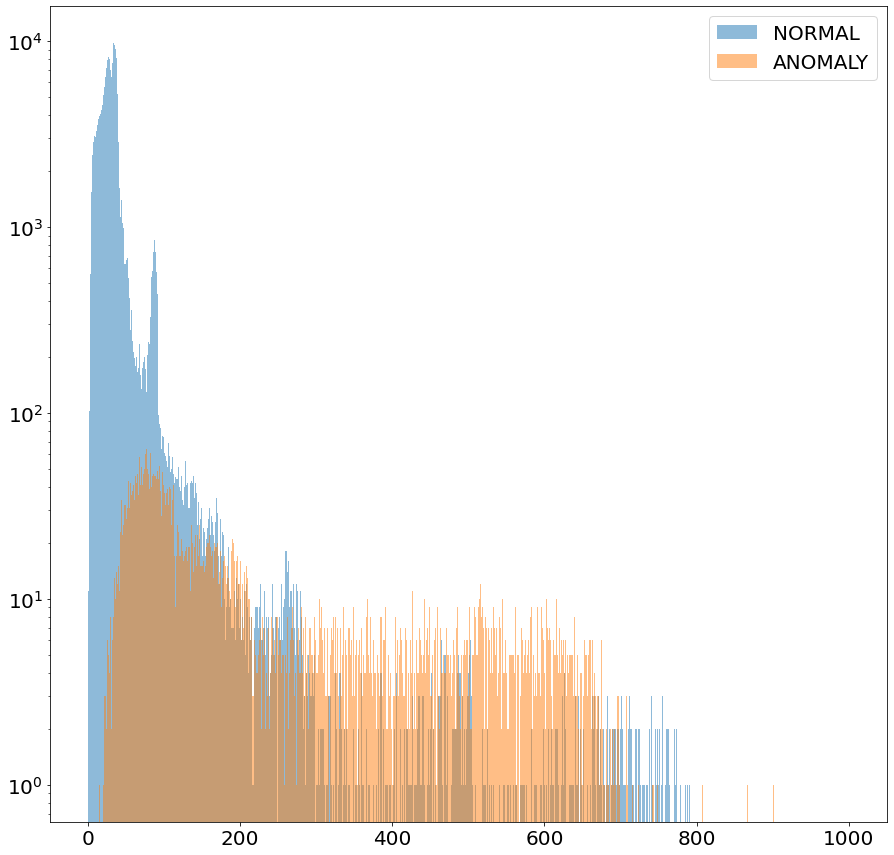
위의 그림은 모든 구간의 데이터를 통합 학습한 모델이 정상과 anomaly 데이터에 대해 출력한 오차의 분포를 나타냅니다. 정상과 anomaly 데이터의 오차가 충분히 분리되지 않네요. 전체 ROC_AUC 값도 0.8에 머물렀습니다. 이것은 각 개별 구간의 특성을 무시하고 전체 데이터를 통합 학습할 때에는 활용 과정에서 정상과 anomaly 데이터를 구분하기 쉽지 않다는 것을 의미합니다.
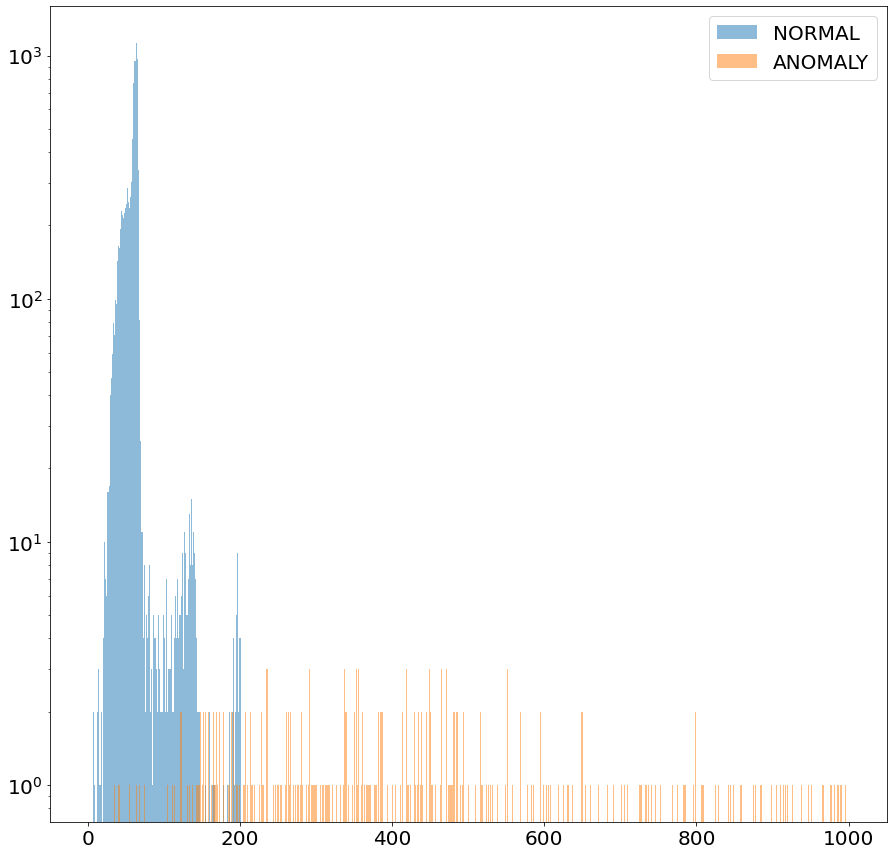
이번에는 특정 구간의 데이터만 추출하여 학습한 모델을 구현하고 테스트해 보았습니다. 이 그림은 임의로 선택한 한 구간의 데이터를 학습한 모델이 출력한 결과입니다. 그림에서 볼 수 있는 바와 같이 정상과 anomaly 데이터의 오차가 충분히 분리되네요. ROC_AUC 값도 0.96을 넘어서는 수치를 보여주었습니다.
이 실험들의 결과만으로 판단하자면, 열차 운행 상태에서 이상 패턴을 탐지하는 모델을 구현하려면 모든 구간의 데이터를 통합해서 활용하는 것보다는 각 개별 구간의 특성을 학습한 모델을 활용할 필요가 있습니다.
열차의 도착 지연 정도의 예측
두번째 실험에서는 운행 중인 열차가 특정 역에 도착할 때 기록할 지연 정도를 이른 시간에 미리 예측 하는 모델을 구현하고 해당 모델의 활용성을 검토하였습니다. 즉 현재의 열차가 기록하고 있는 운행 데이터를 기반으로 앞으로 가야할 역들에 도착할 때 얼마나 예정 시각에 맞게 도착할 지 미리 예측하는 것이죠. 지연 정도는 수치로 표현되므로 Regression 모델을 구현하여 결과를 확인하였습니다.
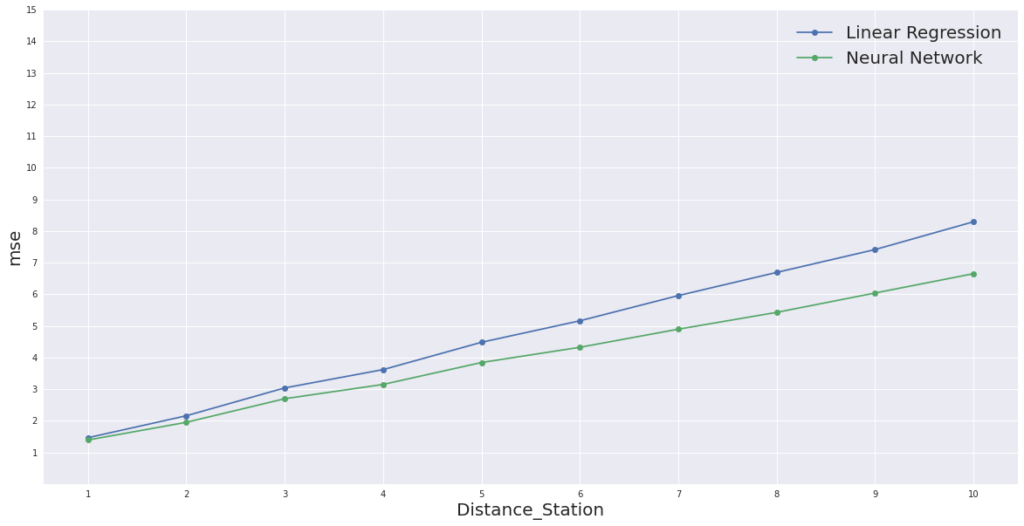
이 그림은 이번 실험에서 구현한 모델이 앞으로 도착할 역들에서의 지연 정도를 예측한 결과와 실제 지연 정도와의 차이, 즉 예측 오차를 나타냅니다. X축의 값이 1인 경우는 바로 다음 역에 도착할 때의 지연 정도를 예측한 것이며 X축의 값이 10인 경우는 10번째 후의 역에 도착할 때의 지연 정도를 예측한 것이죠. 10번째 후의 역에 대한 예측 오차는 약 2분 30초 그리고 바로 다음 역에 대한 예측 오차는 1분 이내를 기록하였습니다. 당연하게도, 멀리 있는 역에 대한 지연 정도의 예측 결과가 가까운 역에 대한 지연 정도의 예측 결과보다 상대적으로 부정확하게 나타납니다.
정리하자면…
이번 포스트에서는 선로 운행 데이터를 바탕으로 운행 상태의 이상을 탐지하는 모델, 그리고 열차의 지연 정도를 최대한 이른 시간에 예측하는 모델의 기초적인 실험결과를 소개하였습니다.
이상 탐지 모델을 활용한 실험을 통해 선로의 위치에 따라 운행 패턴이 다르게 나올 수 있으므로 모든 선로에 대해 이상을 탐지하는 통합 모델을 구현하는 것보다는 각 선로 고유의 특성을 학습하고 이상을 탐지하는 모델을 만드는 것이 효과적일 수 있다는 점을 확인할 수 있었습니다. 지연 정도를 예측하는 과정에서는 최대 10개 역 이전의 위치에 있는 열차가 현재의 역에 도착할 시간의 지연 정도를 예측하는 경우에도 충분히 정확하게 예측할 수 있다는 점을 확인할 수 있었습니다.
이외에도 다양한 분석 주제를 생각해 볼 수 있습니다. 출퇴근 시간대의 열차 운행 패턴은 다른 시간대와 어떻게 다를까요? 광화문이나 시청 광장에서 집회나 행사가 있거나 강남역 주변을 운행하는 버스 노선들 중의 하나가 운행을 멈추면 전철 운행 패턴은 어떻게 변할까요? 이런 상황에서 저는 신도림역에서 열차를 타고 공덕역에 가려고 하는데 약속 시간 안에 도착할 수 있을까요? 갑자기 제가 탄 열차가 서행을 하는데 이유가 뭘까요? 최근 1년 동안 특정 구간에서의 전철 운행 패턴이 지속적으로 변화했다면 혹시 그 구간의 주변에 새로운 아파트 단지가 들어서서 그런 걸까요? 대전에 새로운 전철 노선을 개통하려고 한다면 노선을 어떻게 구성하는게 좋을까요? 이런 분석을 계속 진행하려면 어떤 데이터를, 어떤 장치를 활용해서 수집해야 할까요?


