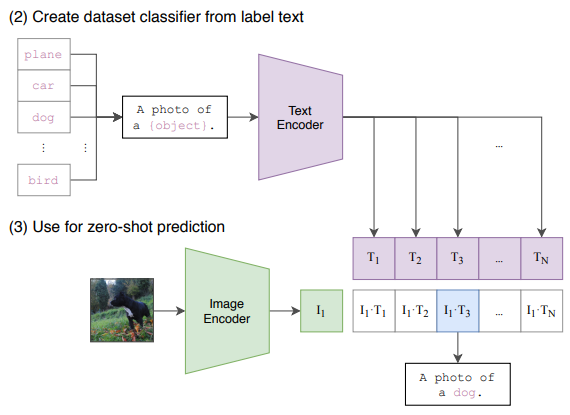
CLIP 논문에서는 (이미지, 물체 분류) 데이터 대신 (이미지, 텍스트)의 데이터를 사용하는데, 수작업 labeling 없이 웹 크롤링을 통해 자동으로 이미지와 그에 연관된 자연어 텍스트를 추출하여 4억개의 (이미지-텍스트) 쌍을 가진 거대 데이터셋을 구축하였다.
(이미지, 텍스트)로 구성된 데이터셋은 정해진 class label이 없기 때문에 분류(classification) 문제로 학습할 수는 없다. 따라서 CLIP 논문에서는 주어진 N개의 이미지들과 N개의 텍스트들 사이의 올바른 연결 관계를 찾는 문제로 네트워크를 학습하였다.
<더보기> 아래의 링크 클릭


