
궁금한 것을 질문하면 대답해 주는 시스템?
살아가면서 수많은 의문이 생긴다. 그리고 그러한 의문들은 비교적 간단한 사실에 대한 것에서부터 (예: 올해의 추석 연휴 기간은?) 치밀한 분석이 필요하거나 주관적인 의견이 녹아들어갈 수도 있는 것들 (예: 세계에서 가장 좋은 대학은? 역대 축구 선수들 중에서 가장 최고의 선수는?) 더 나아가 아주 추상적인 것들 (예: 삶의 의미는 무엇인가? 행복은 상대적이고 주관적인가?)에 이르기까지 다양한 형태를 가질 수 있다.
간단한 사실을 묻는 질문은 구글과 같은 검색엔진을 통해 어렵지 않게 답을 찾을 수 있다. 실제로 “올해 추석 연휴 기간은?”이라는 질문을 구글 검색창에 입력하면 정확한 답을 얻을 수 있다. 그러나 깊은 분석을 요구하거나 주관성, 추상성이 내포된 질문들에 대한 대답을 검색엔진으로부터 바로 얻을 수는 없다. 검색엔진의 역할이 우리의 생활에서 매우 중요한 역할을 하는 것은 사실이지만, 우리가 가지는 모든 종류의 의문들에 대한 대답을 바로 얻는 데에는 현재의 검색엔진만으로는 분명히 한계가 있다. (사실 질문에 대한 답변을 얻기 위해 검색엔진이 만들어진 것은 아니지만.)
요즘에는 인공지능 기술이 크게 발전하고 있다는데, 의문에 대한 답을 내는 것에 대해 의문을 가진 김에, 일상어로 작성한 질문을 입력하면 적절한 답을 해주는 인공지능 시스템을 만들 수 있을 지에 대해서 의문을 가져보자. “내가 그냥 질문을 하면 알아서 잘 대답해 주는 시스템을 만들 수 있는가?”라는 질문을 입력하면 알아서 만족스러운 답을 해주는 시스템을 써서 해결해 버리고 싶은 마음이 들지만 말이다.
Question Answering (QA) 과 Open Domain Question Answering (OpenQA)
Question Answering (QA) 시스템은 자연어로 된 질문 문장(Question Phrase)에 대해 답변을 제공한다. 좀 더 자세히 말하면, 일상적인 어휘의 배열, 즉 문장으로 입력된 질문에 대해 자신이 가진 지식(정보)의 범위 내에서 최적의 답변을 검색, 예측하여 출력한다. 답변은 여러가지 형태(Answer Type)를 가질 수 있는데, 질문과 마찬가지로 문장의 형태를 띠거나, True/False 또는 수치의 형태를 가질 수 있다. QA 시스템이 동작하는 과정에서는 질문의 종류(Question Type)와 질문의 초점(Question Focus)을 분석할 필요가 있으며, 답변을 담고 있을 만한 문장이나 단락(Candidate Paragraph 또는 Candidate Passage)을 찾아내는 작업을 수행하게 된다.
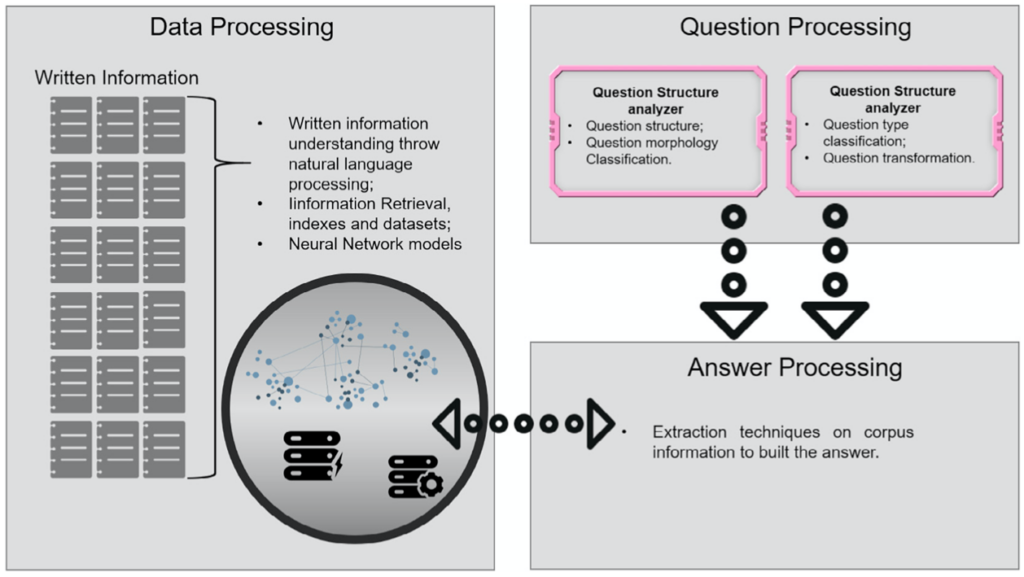
그림 1. QA 시스템의 개념적 구조 (그림 출처 [49])
QA 시스템을 구현할 때에는 입력될 질문의 범위를 미리 정할 수 있다. 또한 답변을 추출할 때 활용할 지식 베이스 (Knowledge Base : KB)를 미리 구축하여 활용할 수 있다. 특히 지식 베이스를 미리 구축할 수 있다면, 시스템이 답변을 찾아내기에 적합한 형태로 미리 가공할 수도 있다. (그림 1의 Data Processing 과정에 해당) 이런 경우에는 질문에 가장 적합한 답변을 선택, 처리하는 과정만 잘 구현하면 원하는 결과를 얻을 수 있다. 물론 지식 베이스에 답변이 들어있지 않을 경우에는 올바른 답변을 제공하기 어렵다.
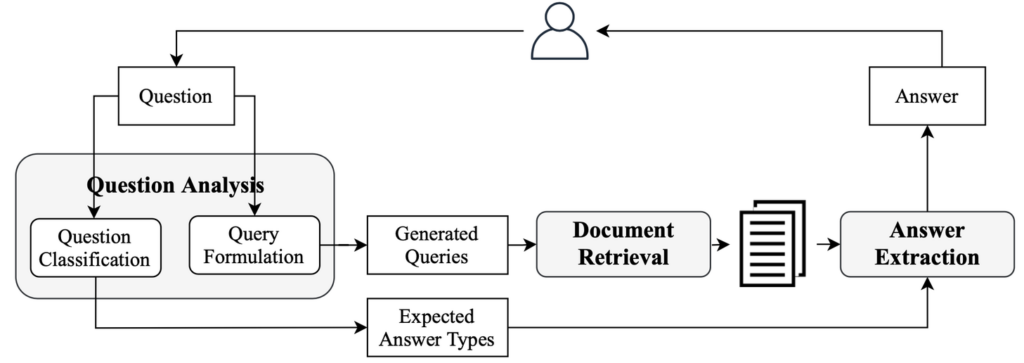
그림 2. 전통적인 Open-domain QA 시스템의 개념 (그림 출처 [1])
이와 달리 Open Domain Question Answering (OpenQA) 시스템은 미리 정해져 있지 않은 범위의 질문에 대해, 광범위한 지식 소스를 활용하여 답변을 제공하는 것을 목표로 한다. 따라서, 질문이 입력되면, 미리 가공되어 있지 않은 (주로 텍스트 형태의) 문서들에 접근하여 답변을 담고 있을만한 Candidate Paragraph들로 찾아야 하며, (그림 2의 Document Retrieval) 찾아낸 Candidate Paragraph들로부터 답변을 추출, 가공하는 작업(Reading Comprehension)도 수행해야 하므로 OpenQA 시스템의 구현 난이도가 더 높다고 할 수 있다.
QA 시스템을 이와 같이 지식 소스의 범위를 기준으로 구분할 수도 있으나 지식 소스의 형태와 활용 방법에 따라 IR-based QA와 Knowledge-based QA로 구분할 수도 있다. IR-based QA는 가공되어 있지 않은 지식 소스를 검색기능을 기반으로 활용하는 개념이고 Knowledge-based QA는 구조적인 형태로 지식 소스를 가공하여 활용하는 개념이다. IBM의 Watson QA 시스템[52]은 이 두가지 개념을 모두 활용하는 하이브리드 형태로 만들어진 것으로 알려져 있다.
어떻게 만드는지 간략하게 알아보자.
전통적인 OpenQA와 딥러닝 기반 OpenQA
(1) 전통적인 Open-domain QA
OpenQA 시스템의 본격적인 동작은 질문이 입력된 후부터 시작된다. 질문이 입력되면 가장 먼저 질문을 이해하기 위해 분석하는 과정이 수행되는데, 질문을 질의로 변환하는 작업(Query Formulation)과 질문의 종류를 판단하는 작업(Query Classification)이 대표적인 수행작업이다. 이렇게 변환된 질의를 써서 답변이 들어있을 가능성이 높은 문서들을 외부 지식 소스로부터 검색(Document Retrieval)한다. 그리고 검색된 결과들로부터 최종적으로 답변을 추출(Answer Extraction)한다. 답변을 추출하는 과정에서는 일종의 필터링 알고리즘이나 랭킹 알고리즘이 동작할 수 있고 Query Classification 결과가 활용될 수 있다. 문서를 검색하는 과정에서 외부 지식 소스로 전통적으로 가장 많이 쓰이는 대상은 Wikipedia [5] 이며, 구글과 같은 검색엔진을 사용하는 경우도 많다. 따라서 전반적으로 검색기능이 중요한 역할을 수행하게 되어 검색 및 필터링 알고리즘의 정확성이 QA 시스템의 전체 성능에 커다란 영향을 미치게 된다.
Query Formulation 과정에서는 POS Tagging, Stemming, Parsing, Stopword Removal 등의 기본적인 프로세스들이 적용되며, 질문 형태의 문장을 검색엔진에 적합한 형태의 질의(Query)로 변환한다. 일반적으로 우리가 검색엔진을 활용할 때 질문 문장 전체를 그대로 입력하기 보다는 주요 키워드들만 떠올린 후에 질의를 만들어 입력한다는 점을 떠올리면 된다. 따라서 이 과정에서는 입력된 질문에서 질문의 의도와 내용을 파악하는데 필요한 주요 어휘들, 그리고 답변을 만들 때 활용할 부가정보들을 추출하는 것이 가장 중요하다. [50, 51] 예를 들어, “한국에서 가장 인구가 많은 도시는?” 이라는 질문이 입력된다면, ‘도시’가 답변이 되어야 한다는 점과 ‘한국’에 초점을 맞춰야 하며 ‘인구가 가장 많다’는 것이 질문의 주요 의도라는 사실을 파악해야 한다. 더 나아가 질문에 들어있는 어휘와 답변에 들어갈 어휘가 동일하지 않을 수도 있고 동일한 의도와 의미를 가지는 다른 형태의 질의가 있을 수도 있다는 점을 고려하여 Query Expansion, Paraphrasing Techniques [9,10,11,12] 등을 적용할 수 있다. 예를 들어, Query Expansion 은 좀 더 정확한 검색 결과를 얻기 위해 질문에 포함된 어휘의 동의어를 찾아 질의에 포함시키거나 Word2Vec[72] 또는 GloVe[73]를 활용하여 벡터로 매핑하여 벡터 공간 내에서 유사한 특성을 가진 다른 어휘를 찾아 추가하는 방법을 쓸 수 있다. 또한 동일 어휘의 다른 형태소를 질의에 추가하는 것도 가능할 것이다.
Query Classification 과정에서는 Question Type(where, when, who, what)을 나누며 이 결과가 Answer Type을 결정한다. 예를 들어 “구글의 설립자는 누구인가?”는 who에 해당하는 질문이므로 답변에는 ‘사람’에 해당하는 정보가 들어있어야 한다. 이러한 정보를 추출하는 과정에는 언어학적(Linguistic) 지식을 기반으로 디자인한 rule들을 활용하거나 type이 미리 레이블링된 대용량의 질문 문장세트를 기반으로 Type Classifier를 학습시켜서 활용할 수 있다. Type Classifier를 만들어 활용할 때에는 각 어휘들의 형태소(Part-of-Speech)와 Named-Entity와 같은 feature 정보들 및 각 어휘의 Embedding Vector를 추출하는 과정이 수행된다.
Document Retrieval 과정에는 검색엔진의 다양한 기법들이 활용될 수 있으며 OpenQA 고유의 필터링이나 랭킹 알고리즘을 추가적으로 구현하여 활용하기도 한다. 예를 들어, Answer Extraction을 위해 검색 결과를 문장, 섹션 또는 단락(paragraph) 단위로 나누어 passage를 만드는 작업을 진행한다. 또한 질문에 들어있는 어휘와 가장 비슷한 어휘를 포함하는 passage가 선택될 수 있도록 해당 passage에 높은 점수를 주거나 Answer Type을 파악한 결과가 ‘사람’일 경우에는 ‘사람’정보가 포함된 passage들로 답변 후보의 범위를 좁힐 수 있다.
Answer Extraction 과정에서는 답변이 들어있을 만한 passage들에 Named Entity Recognition (NER) Technique [39, 45, 63]를 적용하여 Answer Type과 일치하는 것들을 포함하는 passage들을 답변으로 선택하는 것이 가장 기본적인 개념이다. 또한 질문-답변 세트로 이루어진 대용량의 데이터셋을 활용하여 학습시킨 classifier를 사용하기도 한다. 질문에 가장 잘 매칭되는 답변을 찾는 과정에서 문장, 어휘 또는 문법적 구조에서 나타나는 특성들을 활용한다. [53, 54, 55, 56, 13, 14, 15]
사실, Query Formation, Query Classification, Answer Extraction 등의 과정 하나하나가 OpenQA 및 NLP 연구 분야에서는 중요한 연구 주제들이다. 따라서 각각에 대해 깊이있게 알아볼 필요가 있으나, 이에 대한 내용은 후속 글에서 차근차근 펼쳐 보기로 한다.
(2) 딥러닝을 활용한 최근의 OpenQA
전통적인 NLP에서는 어휘나 문장, 문서를 내부적으로 표현할 때 Sparse Vector를 활용하였다. 어휘를 벡터로 표현할 때 표현하고자 하는 어휘에 해당하는 벡터 요소에만 값을 부여하고 나머지는 0으로 표현하거나, TF-IDF, BM25 등과 같은 방법으로 표현한 벡터를 쓰는 경우가 대표적이다. 이러한 표현을 쓰면 벡터의 차원이 불필요하게 커질 뿐만 아니라 어휘의 의미적 특성과 맥락을 표현하는 데에도 한계가 있다. 따라서 최근에는 각 어휘를 작은 차원의 Latent Space 로 매핑하여 벡터의 차원을 획기적으로 줄이면서도 어휘나 문장의 의미적 특성과 맥락 특성을 잘 표현할 수 있는 방법이 많이 제시되었다.
최근에 들어 인공지능 분야의 핵심이 된 딥러닝 모델들과 Natural Language Processing (NLP) 분야의 최대 스타들 중 하나인 BERT[16]를 비롯한 Transformer Model들은 OpenQA 분야에도 커다란 변화를 가져왔다. 간략하게 말하면, 과거에는 질문 또는 답변에 활용할 지식들을 Sparse Vector를 기반으로 표현하여 활용하였다면, 이제는 질문과 답변 데이터들을 모두 Latent (Dense) Vector로 인코딩하여 활용할 수 있게 된 것이다. 더 나아가 맥락에 따라 달라지는 동음이의어와 다의어의 의미도 적절하게 표현할 수 있게 되었다. 따라서 Document Retrieval 과정에서 수행되는 Text Semantic Matching의 정확도도 높아지게 되었다. 이러한 모델은 Answer Extraction 단계에서의 Reading Comprehension 과정에서 가장 크게 활용되어 답변 후보들을 Question-Aware Document Representation으로 표현한다. (BiDAF [17], QANet [18]) 답변 후보가 되는 passage들을 대상으로 특정 토큰(Token)이 답변의 시작이 될 확률과 마지막이 될 확률을 계산하여 가장 높은 확률을 가지는 문장 구간의 시작 인덱스와 끝 인덱스를 선택하는 방식으로 답변을 찾아내는 것이다.
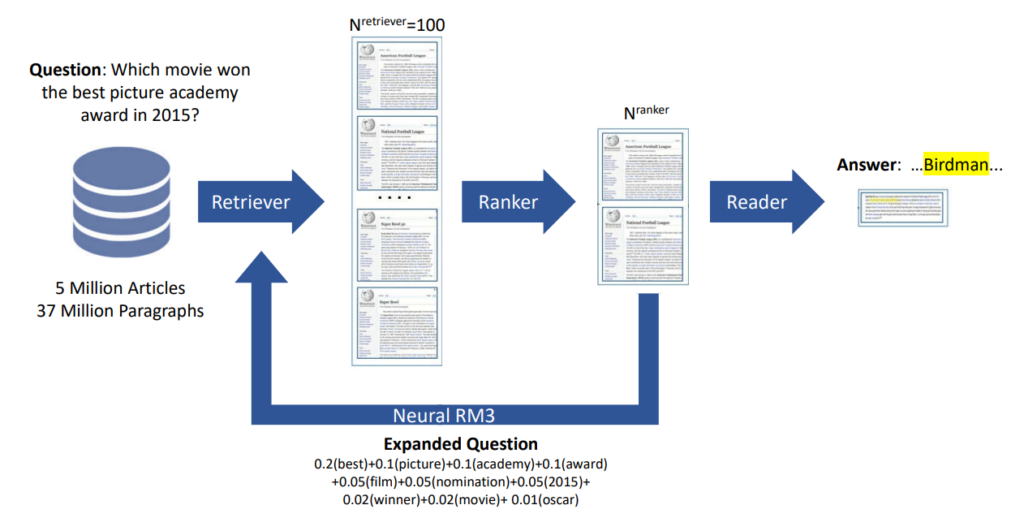
그림 3. Retiever-Reader 구조 (그림 출처 [4])
구조에 따른 분류
(1) Retriever-Reader 구조
Retriever-Reader 구조는 가장 대표적인 형태(그림 3)로서, retriever가 주어진 질문과 관련된 문서를 찾아내고, reader가 그로부터 최종 답안을 선별하여 추출한다. 따라서, retriever는 일종의 검색 시스템이며, reader는 retriever가 검색해낸 결과를 활용한다. 최근까지도 retriever를 TF-IDF나 BM25와 같은 전통적인 Vector Space Model로 구현하고 (Sparse Retriever) reader는 Neural Reading Comprehension Model [19, 35] 로 구현하는 형태가 많이 제시되었다. 이외에도 retriever가 검색한 문서들을 재처리하는 Document Post Processing 모듈이나 reader가 찾아낸 답변 결과들을 재처리하는 Answer Post-processing 모듈이 추가적으로 포함되기도 한다.
Retriever
Retriever를 구현할 때 전통적인 Vector Space Model을 쓸 경우에는 토큰들 사이의 상호작용의 특성이나 Semantic Distance를 고려하는 데에 한계가 있었으므로\, 최근에는 딥러닝 기반의 모델을 써서 이와 같은 한계를 극복하려는 Dense Retriever 모델[46\, 47]이 많이 제시된다. Dense Retriever 모델은 BERT와 같은 모델을 써서 질문과 문서를 각각 인코딩하여 표현한 뒤 둘 사이의 유사도를 측정하는 Representation-based Retriever [24] [39] [46]\, 질문과 문서 사이에서 나타나는 토큰 수준의 상호작용을 잘 잡아내기 위해 질문과 문서를 동시에 입력받는 Interaction-based Retriever\, 그리고 이 두가지 모델의 특성을 합친 Representation-interaction Retriever [48]가 있다.
Complex Question [6, 7]은 하나의 질문에 두 개 이상의 내용을 담고 있어서 여러 내용을 파악하고 추론(Multiple Hop Reasoning [29, 57])해야 답할 수 있는 복합 구조의 질문인데, 이와 같은 질문의 답변은 여러 단계를 거쳐 찾아내기도 한다. 예를 들어, “2002년 한국 축구 국가대표팀 감독이 감독직을 수행했던 잉글랜드 프로축구팀은 무엇인가?”라는 질문에 답하려면 2002년 한국 축구 국가대표팀 감독을 찾아야 할 뿐만 아니라 해당 감독이 맡았던 잉글랜드 프로축구팀에 대한 정보도 찾아야 하는 것이다. 이와 같은 질문에 대응하기 위하여 Iterative Retriever [8]를 활용할 수 있다. Iterative Retriever는 검색 과정을 여러 단계로 구성하여 단계가 진행되면서 이전 단계에서 추출한 결과에 따라 다음 단계의 질의가 변화될 수 있도록 한다. Iterative Retriever를 딥러닝 모델을 써서 구현할 경우에는 질문과 답변이 인코딩된 후 Latent Space 상에서 검색 과정을 진행할 때 질문과 이전 단계의 추출 결과들을 이어 붙인 것을 인코딩하여 새로운 질의 벡터를 만들기도 한다. 이 과정에서 얼마나 많은 수의 단계를 거쳐야 하는가를 정하는 것도 중요한 문제가 되는데, 정확도를 희생시키지 않으면서 효율적으로 검색하는 방법을 만드는 것은 여전히 어려운 과제이다.
Retriever가 검색해 온 문서들에 대한 후처리 과정에서는 모든 답변 후보 passage들에 대해 답을 포함하고 있을 확률을 계산하여 확률이 낮은 것들을 제외시키는 방법을 활용하는데 (일종의 ranking 과정) 최근에는 retrieval과 ranking 모듈을 동시에 학습시키는 Trainable Retriever들이 나오고 있어서 이 모듈의 필요성이 낮아지는 추세이다.
Reader
Reader는 명칭 그대로 답변이 들어있을 만한 문서들을 읽고 입력된 질문이 원하는 답을 찾아내어 제공하는 역할을 하는 모듈이다. Reader는 QA 시스템을 일반적인 검색엔진과 구분되게 하는 가장 중요한 모듈이며, 크게 나누어 Extractive Reader와 Generative Reader로 구분할 수 있다.
Extractive Reader는 입력된 질문에 대한 답변이 retriever가 추출한 passage 내에 반드시 존재한다는 가정 하에 주로 답변의 시작과 끝의 위치(Answer Span)를 예측하는 형태를 취한다. [20, 21, 22, 23, 24, 25, 26, 27, 28] 가장 대표적으로, DrQA Reader [20]은 Multi-layer Bi-LSTM을 써서 질문과 passage들을 입력받아 각 passage로부터 Answer Span들을 추출하고 추출된 것들 중에서 가장 높은 점수를 나타내는 것을 선택한다.
Generative Reader 는 Seq2Seq 모델을 바탕으로 자연어로 된 답변을 생성하는데, BART [33] and T5 [34]와 같은 Pre-trained Seq2Seq Language Models을 써서 답변을 생성하는 Sequence Generator 와 retriever를 함께 학습하는 개념이 대표적이다. [30, 31, 32] 그러나 최종 답변에 문법 오류나 문장의 결합성 부족 등과 같은 문제가 나타나고 있다. [35]
Answer Post-processing 모듈은 reader가 추출한 여러가지 후보 답변들 중에서 최종 답을 찾는데, 이 과정에도 Rule-based Method 또는 Learning-based Method 를 활용할 수 있다. [36, 37, 38]
(2) End-to-End 구조
End-to-End 구조는 Retriever-Reader 구조와는 달리 전체 과정을 하나의 시스템으로 구축하며, retriever 또는 reader 가 없는 형태로 구현하거나 retriever와 reader를 하나의 모듈로 통합하여 구현하는 형태이다. 질문-대답 쌍으로 이루어진 데이터셋을 BERT를 바탕으로 학습, 인코딩하여 Latent Variable 공간에서의 검색 개념을 구현하는 것이 대표적인 방법이다.
ORQA[39]는 질문과 paragraph들 사이의 유사성을 측정하는 과정과 Answer Span을 예측하는 과정을 동시에 수행하도록 학습하는 개념을 제시하여, BERT를 써서 Question-Answer Pairs로부터 retriever와 reader를 통합 학습한다. Pseudo-Question 및 Pseudo-Answer 로 이루어진 데이터셋으로 BERT 기반 모델을 Pre-training한 후에 실제 Question-Answer 데이터셋으로 Fine-tuning하는 과정을 거친다.
대용량의 Pre-trained Model들에 전적으로 의존하여 외부 지식 소스없이 답을 찾게 하는 방법도 제시되고 있다. [42, 43, 44] 이 방법들은 GPT-2 [40], GPT-3 [41], BART [33] and T5 [34]와 같은 Pre-trained Language Models 들이 사전에 파라메터로 담고 있는 정보들을 추가적인 외부 지식 없이 활용하는 개념이기 때문에 답을 찾는 과정에서 retriever를 사용할 필요가 없다. Pre-trained Model들은 Zero-shot Manner로 사용되거나 질문-답변 쌍으로 이루어진 데이터셋을 바탕으로 Fine-tuning 하는 과정을 거칠 수 있다.
DenSPI [45]는 retriever 만으로 구성하는 개념을 제시하였는데, Phrase Level의 Embedding Index를 구축하고 질문과 문장을 Sparse Vector (예: tf-idf 벡터) 와 Dense Vector (예: BERT encoder)를 이어붙여 표현한 뒤에 FAISS[58]를 기반으로 유사도를 측정하여 답변을 검색하는 방법이다.
풀어야 할 문제들
OpenQA 시스템의 사용성을 높이기 위해서는 retriever와 reader의 성능이 향상되어야 한다는 것은 말할 필요도 없을 것이다. Retriever의 검색 결과에서 노이즈를 제거하거나 좀 더 정확한 랭킹을 부여하는 방법에 대한 것이 이것에 해당될 것이다. 그러나 OpenQA 연구자들은 이외에도 다양한 방법으로 OpenQA 시스템의 발전을 꾀하고 있다.
OpenQA 시스템은 외부 지식 소스 또는 내부 파라메터의 형태로 지식을 보유하고 활용해야 하는데 이러한 지식에 ‘상식(Common Sense)’ 또는 특정 분야의 ‘전문적 지식’(Domain Specific Knowledge)을 포함시키는 것이 필요할 수 있다. 이렇게 포함된 지식들은 OpenQA의 내부 모듈이 찾아낸 후보 답변들의 타당성을 평가하는 데에 활용될 수 있다. 물론 이를 위해서는 ‘상식’과 ‘전문적 지식’에 해당하는 지식 소스를 통합하여 활용해야 한다. 이러한 지식은 DBPedia [60], Freebase [61] and Yago2 [62]와 같은 지식 베이스(KB) 형태를 띠거나 Pre-trained Language Model의 파라메터 형태[46, 24, 39, 65, 66]로 저장, 활용될 수 있다. IBM Watson의 DeepQA[59]는 웹검색엔진과 지식 베이스를 통합, 활용하며 QuASE[63]는 지식 베이스를 활용하여 답변의 타당성을 검토하게 한다. Graft-Net[64]과 GraphRetriever[67]은 Graph Convolution based Neural Network을 활용하여 지식 베이스를 구축하고 최종 답변을 추론하는 과정에 활용한다.
OpenQA 연구자들은 Conversational OpenQA의 필요성에 대해서도 언급하고 있다. 이것은 질문이 모호하거나 지식 소스가 충분하지 않을 경우 질문을 좀 더 명확하게 하기 위한 추가 질문을 제기하여 대화를 생성하고 모델링하는 과정에 대한 것이다.
Complex Question에 대한 답변을 찾는 과정 – Multi-hop Question Answering – 또한 발전의 여지가 남아있다. Multi-hop Question Answering 시스템은 여러 개의 문서들에서 답을 찾아야 하므로 retriever 및 reader의 구조가 복잡해지게 된다. Wikipedia 데이터로부터 각 passage가 노드이고 hyperlink가 edge인 graph를 만들고 Recurrent Retrieval 방식을 적용한 PathRetriever [68, 69]가 대표적이다.
그러나 무엇보다도 OpenQA 시스템이 사용성을 확보하려면 빠른 시간 안에 답변을 찾아낼 수 있어야 한다. 빠른 처리를 위해 시스템이 활용할 모든 지식들을 미리 프로세싱하여 인덱싱하거나 메모리 사용량을 줄이기 위해 압축 기술을 적용할 수 있다. 또한 Dense-Vector와 Sparse-Vector를 적절히 통합 활용하여 속도를 높일 수 있다. [45, 71]
References & Further readings
- [1] https://arxiv.org/abs/2101.00774
- [2] https://cdsciavolino.github.io/static/media/Open_QA_Survey.48d5c240.pdf
- [3] https://aclanthology.org/2020.acl-tutorials.8.pdf
- [4] https://arxiv.org/pdf/2009.00914.pdf
- [5] https://www.wikipedia.org/
- [6] https://arxiv.org/abs/2007.13069
- [7] https://aclanthology.org/P17-2049/
- [8] https://github.com/qipeng/golden-retriever
- [9] https://aclanthology.org/W04-3219.pdf
- [10] https://aclanthology.org/P05-1074/
- [11] https://aclanthology.org/P08-1116/
- [12] https://aclanthology.org/W10-4223/
- [13] https://dl.acm.org/doi/10.1145/160688.160717
- [14] https://www.academia.edu/2038325/Using_syntactic_and_semantic_relation_analysis_in_question_answering
- [15] https://aclanthology.org/I05-1045/
- [16] https://arxiv.org/abs/1810.04805
- [17] https://arxiv.org/abs/1611.01603
- [18] https://arxiv.org/abs/1804.09541
- [19] https://stacks.stanford.edu/file/druid:gd576xb1833/thesis-augmented.pdf
- [20] https://arxiv.org/abs/1704.00051
- [21] https://arxiv.org/abs/2004.04906
- [22] https://arxiv.org/abs/1709.00023
- [23] https://arxiv.org/abs/1905.05733
- [24] https://arxiv.org/abs/2002.08909
- [25] https://aclanthology.org/P18-1161/
- [26] https://aclanthology.org/P19-1222/
- [27] https://arxiv.org/abs/1902.01718
- [28] https://arxiv.org/abs/1911.03868
- [29] https://arxiv.org/abs/1710.06481
- [30] https://arxiv.org/abs/2005.11401
- [31] https://arxiv.org/abs/2009.12756
- [32] https://arxiv.org/abs/2007.01282
- [33] https://arxiv.org/abs/1910.13461
- [34] https://arxiv.org/abs/1910.10683
- [35] https://arxiv.org/abs/1907.01118
- [36] https://arxiv.org/abs/1810.00494
- [37] https://arxiv.org/abs/1711.05116
- [38] https://arxiv.org/abs/1906.03008
- [39] https://arxiv.org/abs/1906.00300
- [40] https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
- [41] https://arxiv.org/abs/2005.14165
- [42] https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
- [43] https://arxiv.org/abs/1810.04805
- [44] https://arxiv.org/abs/1907.11692
- [45] https://arxiv.org/abs/1906.05807
- [46] https://arxiv.org/abs/2004.04906
- [47] https://github.com/facebookresearch/DPR
- [48] http://arxiv.org/abs/2007.00814
- [49] https://www.sciencedirect.com/science/article/pii/S131915781830082X
- [50] https://arxiv.org/abs/1808.09492
- [51] https://dl.acm.org/doi/abs/10.1145/2124295.2124349
- [52] https://www.ibm.com/blogs/research/2018/02/open-domain-qa/
- [53] https://nlp.stanford.edu/mengqiu/publication/LSII-LitReview.pdf
- [54] https://trec.nist.gov/pubs/trec10/papers/insight_trec10.pdf
- [55] https://aclanthology.org/P02-1006.pdf
- [56] https://homes.cs.washington.edu/\~weld/papers/mulder-www10.pdf
- [57] https://arxiv.org/abs/1910.07000
- [58] https://github.com/facebookresearch/faiss
- [59] https://ojs.aaai.org//index.php/aimagazine/article/view/2303
- [60] https://link.springer.com/chapter/10.1007/978-3-540-76298-0_52
- [61] https://dl.acm.org/doi/10.1145/1376616.1376746
- [62] https://www.sciencedirect.com/science/article/pii/S0004370212000719
- [63] https://dl.acm.org/doi/10.1145/2736277.2741651
- [64] https://arxiv.org/abs/1809.00782
- [65] https://arxiv.org/abs/1902.01718
- [66] https://arxiv.org/abs/2009.08553
- [67] https://arxiv.org/abs/1911.03868
- [68] https://arxiv.org/abs/1911.10470
- [69] https://hotpotqa.github.io/
- [70] https://arxiv.org/abs/1911.02896
- [71] https://arxiv.org/abs/1301.3781
- [72] https://nlp.stanford.edu/pubs/glove.pdf


